VMware 担当者コラム
VMware
vSAN6.7U3に関するTipsとパフォーマンス改善ポイントについて
こんにちは、VMware担当の及川です。
今回は11月に行われた、vForumで聴講したセッションの中で、vSANに関するTipsが紹介されておりましたので、皆様に共有させて頂きます。
今回ご紹介する内容は、vSANクラスタの再起動及びシャットダウンに関する事項とvSAN6.7Update3(以下vSAN6.7U3)のパフォーマンスの改善点なります。
■vSANクラスタで全てのホストを同時に再起動する際に単一障害により、利用不可のデータが発生する
<概要>
クラスタのメンテナンスを実行する際に再起動後、「アクション不要のメンテナンスモード」機能を使用すると、クラスタ起動中に障害が発生した場合、メンテナンス後にデータが使用できなくなることがあります。複数の ESXi ホストで再起動またはメンテナンスを 1台ずつ実行するのは安全ですが、複数のホストを同時に再起動すると、この問題が発生することがあります。
vSAN 6.7U3未満と以降で対処の方法がそれぞれ異なるため、該当のKBについてご案内します。
【vSAN6.7U3未満の環境】
日本語のKBが出ておりましたので、以下URLに沿ってご対応ください。
かなり手順が複雑です。。。
https://kb.vmware.com/s/article/60424?lang=ja&queryTerm=60424
【vSAN6.7U3以降の環境】
こちらは英語のKBが出ておりました。かなり簡素化されております。
https://kb.vmware.com/s/article/70650
以下、手順となります。
-
クラスタ内のホストを再起動する前に、どれか一つのホストにログインしてください。(Witnessは除く)
-
ホスト上で、Pythonプログラムを実行
python /usr/lib/vmware/vsan/bin/reboot_helper.py prepare -
コマンド実行後'Cluster preparation is done'と出力されるのを待ちます。
-
エラーがこの段階で発生した場合、エラーメッセージに基づいて問題を解決し、再びステップ#3を試してみてください。
-
クラスタ内に正常でない/切断されたホストがある場合は、それらを回復/削除してRetryしてください。
-
-
「アクションなし」モードですべてのホストをメンテナンスモードにします。
-
再起動/シャットダウンを続行します。
-
すべてのホストがリブート/シャットダウンから復帰したら、すべてのホストをメンテナンスモードから終了します。
-
もし、起動に失敗したホストがある場合、vSANクラスタから不良ホストを手動で回復または移動します。
-
-
クラスタ内のホストの1つ(監視ホストを除く)にログインします。 ホストでコマンドを実行します。
python /usr/lib/vmware/vsan/bin/reboot_helper.py recover -
コマンドが返されるまで待ち、'Cluster reboot/power-on is completed successfully!'が出力されれば完了です。
■パフォーマンスの改善(vSAN6.7U2との比較)
大きく以下、3点の改善項目がございます。
-
一貫した性能
-
書き込み遅延のバラつきを少なくし、I/Oフロー制御の改善
-
-
より高いスループット
-
キャッシュでステージング(最終確認を行う段階)中のプロアクティブなI/Oバッファリング
-
重複除外のタスクの平行化
-
-
より迅速な再同期
-
異なる書き込みI/Oのステージ間のタスク平行化
-
実際の検証結果は、以下の通りです。
-
ストレージポリシーやランダム、シーケンシャルアクセスによって異なりますが、IOPSの向上(10%~25%程度)、Read/Writeの遅延(10%~20%程度)削減
-
CPUのオーバーヘッドの改善
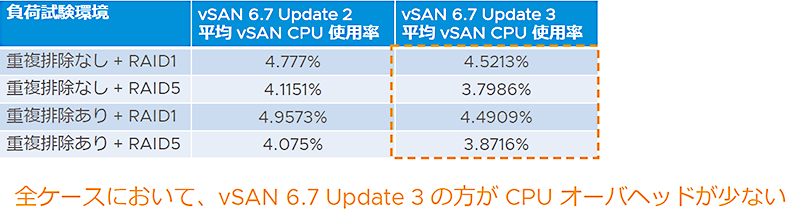
-
1TBの再同期について

いかがでしたでしょうか?
シャットダウンについては、2つの手順を見比べると、vSAN6.7U3ではかなり手順が簡素化されております。また、パフォーマンスも大幅に改善されていることが分かります。vSANのメリットを享受するためには継続的なUpdateが必要となりますので、可能であればvSAN6.7U3に是非Updateください。
VMwareの記事

※閲覧にはiDATEN(韋駄天)へのログインが必要です。